
Family Classification (Track 2)
Provided multiple members from a set of known families (i.e., classes), the goal is to model each family (i.e., build a classifier) to determine which of these families a set of unseen subjects belongs to. Thus, Family Classification is an one-to- many problem.
Challenge portal is open to all individuals and teams! Register now at CodaLab, https://competitions.codalab.org/competitions/16742.
Challenge portal is open to all individuals and teams! Register now at CodaLab, https://competitions.codalab.org/competitions/16742.
Intended Use
Family classification focuses on a slightly different problem: given a facial image, find the family to which the face of the image belongs to, i.e., families are modeled using facial images of other family members. Essentially, it is an one-to-many recognition problem, and becomes more challenging with an increasing number of families, as families contain large intra-class variations that typically fools the feature extractors and classifiers. Similar to conventional facial recognition, when the target data are unconstrained faces in the wild (e.g., variations in pose, illumination, expression, etc.), the task gets increasingly more difficult, as it is breaching capable of handling real-world scenarios. These are, unfortunately, challenges that need to be addressed with family recognition as well, i.e., the capability to recognize unconstrained families in the wild are needed in order to advance such technology for practical use.
For Family Recognition, there is a pre-specified gallery of facial images, for which all family labels are provided. The goal is to identify the family labels for a set of unseen faces. For example, the gallery could be composed of 25 families, each with at 25 facial images of at least 5 family members. The task is then to determine which of the 25 families the unseen input face belongs to.
Note the the set of unseen, test facial images are of individuals that are not included in the gallery (e.g., assuming the minimum of 5 members makes up a family in the gallery, none of these 5 individuals will be used for testing, as additional, unseen family members will be).
For Family Recognition, there is a pre-specified gallery of facial images, for which all family labels are provided. The goal is to identify the family labels for a set of unseen faces. For example, the gallery could be composed of 25 families, each with at 25 facial images of at least 5 family members. The task is then to determine which of the 25 families the unseen input face belongs to.
Note the the set of unseen, test facial images are of individuals that are not included in the gallery (e.g., assuming the minimum of 5 members makes up a family in the gallery, none of these 5 individuals will be used for testing, as additional, unseen family members will be).
Data Splits
FIW includes a total of 1,000 families with multiple samples for each of the members. Thus, the range of modern-day data-driven approaches (i.e., deep learning models) that is now possible opens doors to possibilities in terms of proposed solutions to the problem of family classification.

Photos of families sampled randomly from FIW (i.e., 27 of 1, 000).
The data for family classification is split into 3 disjoint sets referred to as Train, Validation, and Test sets-- ground truth for training data will be provided during Phase 1, while submissions for the validation data can be uploaded for scoring. Then, ground truth for the validation data will be made available during Phase 2. Lastly, the "blind" Test set will be released during Phase 3. No labels will be provided for the Test set until the competition is adjourned. Teams are asked to only process the Test set to generate submissions and, hence, any attempt of analyzing or understanding the Test set is prohibited. Training and Validation are made up of 227 unique families, while others will be released for testing.
Evaluation Settings and Metrics
The results for this multi-class problem will be reported as top 1% error ratings and visualized as confusion matrices.
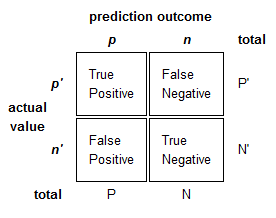
View of confusion measures used for Family Classification.